

Lost data, Two approaches to DIY Data Recovery from logical damage or corruption.
In this article we’ll look at two approaches to diy data recovery. In part 1 we have discovered there are two causes for data loss: physical disk issues and logical damage. At this point we assume logical damage as addressing physical is something that often requires specialized equipment, software and experience. it is best left to a professional data recovery engineer.
Basically there are two ways to recover data from logical damage or corruption: We can either try to get the important data off the disk and copy it somewhere else, or we can try to fix whatever disk structures are corrupt.
1. ‘Fix’ the logical damage – Approach 1.
One flipped bit at the wrong place, and an entire disk may appear to be empty!
We get this asked a lot: If data recovery software can find lost files, why not simply add those files to the indexes, the disk and file system structures again? Just flip those bits back! It is indeed true that by adding 16 bytes in the partition table, and lost partition can be brought back to life again.
In the ‘old days’, the DOS days, the pre and early Windows days, this was the way of doing things. For example to undelete a file, you used an undelete utility to simply ‘add’ deleted files to the file system again. All the tool would ask you was to enter the first character of a filename (which was replaced by a special character during the delete, and the utility would make a best guess at the FAT and directory and modify that for you. The previously deleted files simply re-appeared in the directory listing.
The first DIY Data Recovery and disk tools I wrote worked just like that, and so does our DOS tool DiskPatch which is still available (www.diydatarecovery.nl): To recover a deleted volume or partition, it scans the disk to determine the file system for the lost volume, and the start position and size. With that information it can modify the partition table, and voila, the volume is back.
Seems to be the easiest and fastest way out, isn’t it? There are however disadvantages associated with this approach:
- It requires a certain degree of understanding of underlying disk structures from the user. For example, it’s not uncommon that after scanning a disk that more partitions are detected than expected. It is not uncommon that more files are detected than expected. Software can sometimes not decide which of multiple valid partitions, or files are the ones that need to be ‘recovered’. So then the burden of that decision is with the user of the software.

DiskPatch: Select partitions to undelete. Do you know which one?
- What follows is that the result of the recovery becomes unpredictable. While the changes, the repairs themselves can often be reversed or undone by the software, modifications made to the disk that occur after the repair can not. It may very well be possible that Windows looks at the repaired volume and decide to run chkdsk that starts fixing file system issues. If as a result of that data disappears again then you have even bigger problems. NTFS disk structures are undocumented (unless you pay), and many flavors of Linux, and also data recovery software rely on reverse engineering NTFS. Editing NTFS disk structures is therefor always a bit of a gamble, and Windows chkdsk often fixes issues by deleting the offenders.
- Even if used software has the ability to undo repairs/changes made to the disk, this is far from 100% fail-safe. Backups people make fail all the time, the same can happen to the undo archive the disk repair software created.
I have seen people using DiskPatch swapping disks causing DiskPatch to lose track of which undo archive corresponded with what disk. And then a mistake is easily made or the software may simply refuse to restore the undo archive.
That all being said, under conditions it may be safe to repair a disk, but consensus is that it is safer to use the second approach.
2. Copy data off the damaged or corrupted drive – Approach 2.
Rather than repairing a disk, data recovery software will be used to scan a disk (read-only) and rebuild a ‘virtual file system’ in memory based on the data it detects. The files and folders in the virtual file system are then presented in an explorer like view. From there the user selects folders and files for recovery which the software then copies to another disk.
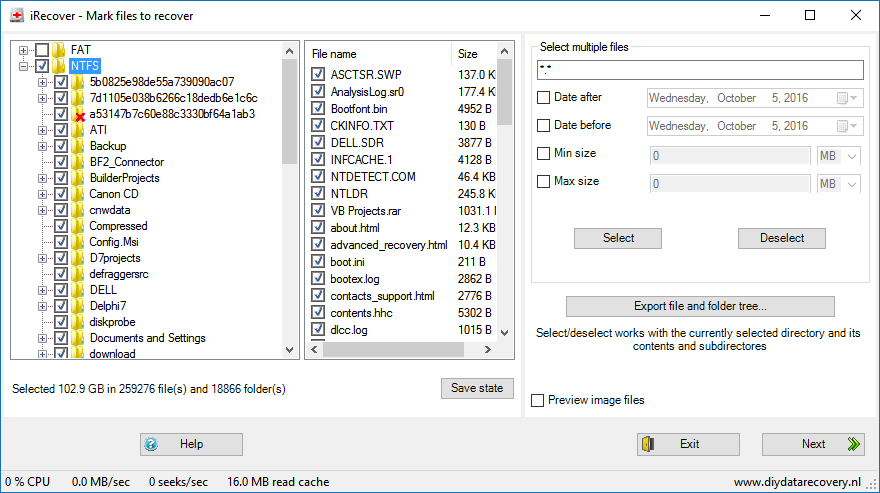
Approach 2: mark files and copy them to another disk
As mentioned before, data recovery software typically picks up more folders and files than that were present on the file system. As a consequence, if the user wants to copy all detected files and sort through them later, the receiving disk must be able to store all the selected files and folders, which may be more than expected.
The advantage of data extraction is that the data recovery software accesses the ‘victim’ disk read-only so logical damage doesn’t get worse, and it allows the user to try alternative software if recovery the tool was originally picked for the task doesn’t yield results.