

Self-Monitoring, Analysis, and Reporting Technology – S.M.A.R.T.

S.M.A.R.T. (often written as SMART) is a monitoring system built in to Hard Disks and SSDs, to detect and report parameters that can help determine a disk’s reliability. Although SMART can help determine a disk’s current state and possibly (future) failures, not all disk failures are predictable. It is important to keep that in mind when interpreting SMART data attributes.
S.M.A.R.T. data is used by:
- The PC BIOS
- Windows
- Utility Software
Use the iRecover SMART window to determine a disk’s condition.
iRecover contains an on-demand S.M.A.R.T. tool that allows you to determine the current state of the disk:
In the ‘Disks and Partitions’ list select a physical disk > Click ‘More Functions’ > Select SMART Information.
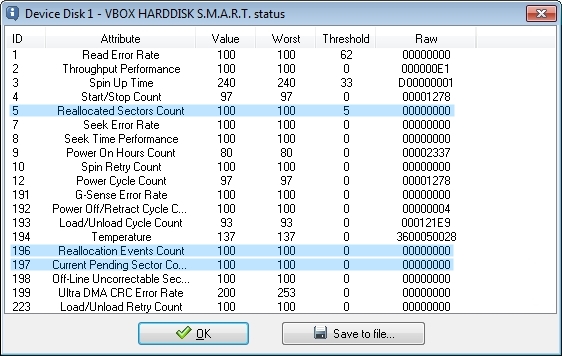
S.M.A.R.T. attributes window iRecover
I have highlighted the important attributes that can be used to examine a disk’s physical condition. High raw values for the ‘Reallocated Sector Count’ and/or ‘Current Pending Sector Count’ are reason for concern and it may be wise to clone or image the disk first. If you want me to help you interpret SMART data, click ‘Save to file’, and email me the file (joep@disktuna.com)
iRecover is a ‘dumb’ SMART data ‘messenger’, it just gets the data and displays it. It does not interpret values, nor does it monitor SMART data over a longer period. It is however useful for quickly determining the physical state of the disk.
Keeping an eye on your hard disk’s health.
Although I try to run as little software in the background as possible (as you may have guessed from the DiskTuna description on this site’s home page), I do make a few exceptions: I run anti virus software and I run a S.M.A.R.T. monitor.
By running a S.M.A.R.T. monitor constantly in the background you will be warned when a disk is (about to be) failing on you. As a SMART monitor is watching the disk over a longer period of time it can even try to make some predictions on when a disk may fail in the future. Also, a program like HD Sentinel can even out-smart the built-in failure prediction of a disk (which is basically nothing more than a ‘pre-fail’ attribute exceeding threshold) based on loads of experience with loads of different hard disks. But again, keep in mind that not all hard disk failures can be predicted!
When a hard disk fails or dies, DIY data recovery is hardly ever an option! If a disk fails and data was not backed up, you almost always have to go the expensive route to recover the data: sent the disk to a data recovery lab.
Utilities that keep an eye on your disk’s health:
| HD Sentinel |
|---|
| HD Sentinel info and purchase URL. HD Sentinel website |
| Active SMART |
| Active SMART purchase URL Active SMART website |
S.M.A.R.T. Attributes
To predict failures and/or to display S.M.A.R.T. information. For example, a PC may warn the user during the boot process that a disk is about to fail and data needs to backed up ASAP. There are numerous utilities available that either run on-demand to display current S.M.A.R.T. data, or that monitor S.M.A.R.T. data all the time while running in the background. S.M.A.R.T. data is typically displayed in an attribute list using columns for the different SMART attributes:
| Attribute | Value | Worst | Threshold | RAW value |
| Attribute ID and name | The current normalized value for the attribute. 1 generally is worst, 253 best. | Worst normalized value that was ever detected. 1 generally is worst, 253 best. | The critical value. Once the value is reached the attribute ‘fails’. Note however that not all attributes are ‘pre-fail’ attributes. | The RAW data. So for example, for the attribute ‘Reallocated Sector Count’, the value would display actual number of reallocated sectors. |
Attributes are being used to retrieve current psychical/logical state of a drive and to show their meaning in much more readable form for end-user. Threshold is the critical value for an attribute. Any value lower than (or equal to) threshold means decreased performance or even hard disk failure.
SMART utilities can display less or additional columns. Sometimes the RAW value for an attribute is hidden. Many show an extra column displaying ‘OK’ or ‘FAIL’. Thus making it easier to determine which attributes are problematic
Flags
Each attribute can have a certain collection of flags:
| Flag name | Description |
|---|---|
| Pre-failure warranty attribute (PW) | Indicates a pre-failure condition (caused by exceeded threshold) where imminent loss of data is being predicted (life critical attribute). |
| Online collection attribute (OC) | Indicates that the value of this attribute is calculated during Online test. |
| Performance attribute (PE) | Indicates degradation of performance caused by usage or age of a drive. |
| Error rate attribute (ER) | Indicates that attribute measure frequency of errors. |
| Error count attribute (EC) | Indicates that attribute is a counter of events. |
| Self-preserving attribute (SP) | Indicates that attribute is automatically preservable and restored each time when performing S.M.A.R.T. tests. |
Known attributes
| ID | Name of attribute | Description |
|---|---|---|
| 0 | ATTR INVALID | Invalid attribute |
| 1 | Raw Read Error Rate | Frequency of errors appearance while reading RAW data from a disk. Lower RAW value is better. |
| 2 | Throughput Performance | Overall (general) throughput performance of a hard disk drive. Higher RAW value is better. |
| 3 | Spin Up Time (ms) | Time needed by spindle to spin-up |
| 4 | Start/Stop Count | Number of start/stop cycles of spindle |
| 5 | Reallocated Sector Count | Count of reallocated sectors. The raw value normally represents a count of the bad sectors that have been found and remapped |
| 6 | Read Channel Margin | Reserve of channel while reading |
| 7 | Seek Error Rate | Frequency of errors appearance while positioning |
| 8 | Seek Time Performance | The average efficiency of operations while positioning |
| 9 | Power-On Count (hrs or min) | Quantity of elapsed hours (or minutes) in the switched-on state |
| 10 | Spin-up Retry Count | Number of attempts to start a spindle of a disk |
| 11 | Calibration Retry Count | Number of attempts to calibrate a drive |
| 12 | Power Cycle Count | Number of complete start/stop cycles of hard disk |
| 13 | Soft Read Error Rate | Frequency of “program” errors appearance while reading data from a disk |
| 22 | Current Helium Level | Specific to He8 drives from HGST. This value measures the helium inside of the drive specific to this manufacturer |
| 170 | Available Reserved Space | Number of physical erase cycles completed on the drive as a percentage of the maximum physical erase cycles the drive is designed to endure |
| 171 | SSD Program Fail Count | (Kingston) The total number of flash program operation failures since the drive was deployed |
| 172 | SSD Erase Fail Count | (Kingston) Counts the number of flash erase failures |
| 173 | SSD Wear Leveling Count | Counts the maximum worst erase count on any block |
| 174 | Unexpected power loss count | Raw value reports the number of unclean shutdowns |
| 175 | Power Loss Protection Failure | Last test result as microseconds to discharge cap |
| 176 | Erase Fail Count | S.M.A.R.T. parameter indicates a number of flash erase command failures |
| 177 | Wear Range Delta | Delta between most-worn and least-worn Flash blocks. It describes how good/bad the wear-leveling of the SSD works on a more technical way |
| 179 | Used Reserved Block Count Total | Pre-Fail attribute used at least in Samsung devices |
| 180 | Unused Reserved Block Count Total | Pre-Fail attribute used at least in HP devices |
| 181 | Program Fail Count Total | Total number of Flash program operation failures since the drive was deployed |
| 182 | Erase Fail Count | Pre-Fail Attribute used at least in Samsung devices |
| 183 | SATA Downshift Error Count | Western Digital, Samsung or Seagate attribute: Total number of data blocks with detected, uncorrectable errors encountered during normal operation |
| 184 | End-to-End error | Count of parity errors which occur in the data path to the media via the drive’s cache RAM |
| 185 | Head Stability | Western Digital attribute |
| 186 | Induced Op-Vibration Detection | Western Digital attribute |
| 187 | Uncorrectable Errors | The count of errors that could not be recovered using hardware ECC |
| 188 | Command Timeout | The count of aborted operations due to HDD timeout. Normally this attribute value should be equal to zero |
| 189 | High Fly Writes | If an unsafe fly height condition is encountered, the write process is stopped, and the information is rewritten or reallocated to a safe region of the hard drive. This attribute indicates the count of these errors detected over the lifetime of the drive. |
| 190 | Airflow Temperature | Airflow temperature on Western Digital HDs |
| 191 | G-Sense Error Rate | The count of errors resulting from externally induced shock and vibration |
| 192 | Power-Off Retract Cycle | Number of power-off or emergency retract cycles |
| 193 | Load/Unload Cycle Count | Count of load/unload cycles into head landing zone position |
| 194 | HDA Temperature (°C) | Temperature of a Hard Disk Assembly |
| 195 | Hardware ECC Recovered | Frequency of the on the fly errors (Fujitsu: ECC On The Fly Count) |
| 196 | Reallocated Event Count | Count of remap operations |
| 197 | Current Pending Sector Count | Current count of unstable sectors (waiting for remapping) |
| 198 | Off-line Scan Uncorrectable Count | Count of uncorrected errors |
| 199 | UltraDMA CRC Error Rate | Total count of errors CRC during UltraDMA mode |
| 200 | Write Error Rate | Count of errors appearance while recording data into disk (Western Digital: Multi Zone Error Rate) |
| 201 | Soft Read Error Rate I | Count of the off track errors (Maxtor: Off Track Errors) |
| 202 | Data Address Mark Errors | Count of the Data Address Mark errors |
| 203 | Run Out Cancel | Count of the ECC errors (Maxtor: ECC Errors) |
| 204 | Soft ECC Correction | Count of errors corrected by software ECC |
| 205 | Thermal Asperity Rate | Count of the thermal asperity errors |
| 206 | Flying Height | The height of the disk heads above the disk surface |
| 207 | Spin High Current | Quantity of used high current to spin up drive |
| 208 | Spin Buzz | Quantity of used buzz routines to spin up drive |
| 209 | Offline Seek Performance | Drive’s seek performance during offline operations |
| 210 | Vibration During Write | Found in Maxtor 6B200M0 200GB and Maxtor 2R015H1 15GB disks |
| 211 | Vibration During Write | A recording of a vibration encountered during write operations |
| 212 | Shock During Write | A recording of shock encountered during write operations |
| 220 | Disk Shift | Shift of disk is possible as a result of strong shock loading in the store, as a result of it’s falling or for other reasons (sometimes: Temperature) |
| 221 | G-Sense Error Rate II | The count of errors resulting from externally induced shock & vibration (dropping drive, for example) |
| 222 | Loaded Hours | Loading on drive caused by the general operating time of hours it stores |
| 223 | Load/Unload Retry Count | Loading on drive caused by numerous recurrences of operations like: reading, recording, positioning of heads, etc. |
| 224 | Load Friction | Loading on drive caused by friction in mechanical parts of the store |
| 225 | Load/Unload Cycle Count II | Total of cycles of loading on drive |
| 226 | Load-in Time | General time of loading for drive |
| 227 | Torque Amplification Count | Quantity efforts of the rotating moment of a drive |
| 228 | Power-Off Retract Count | Quantity of the fixed turning off’s a drive |
| 230 | Drive Life Protection Status | Current state of drive operation based upon the Life Curve |
| 231 | SSD Life Left | Indicates the approximate SSD life left, in terms of program/erase cycles or Flash blocks currently available for use |
| 232 | Available Reserved Space | Intel SSD reports the number of available reserved space as a percentage of reserved space in a brand new SSD |
| 233 | Media Wearout Indicator | Intel SSD reports a normalized value of 100 (when the SSD is new) and declines to a minimum value of 1 |
| 234 | Avg Erase Count AND Max Erase Count | Decoded as: byte 0-1-2 = average erase count (big endian) and byte 3-4-5 = max erase count (big endian) |
| 235 | Good Block Count | Decoded as: byte 0-1-2 = good block count (big endian) and byte 3-4 = system (free) block count |
| 240 | Head Flying Hours | Time while head is positioning |
| 241 | Total LBAs Written | Total count of LBAs written |
| 242 | Total LBAs Read | Total count of LBAs read |
| 243 | Total LBAs Written Expanded | The upper 5 bytes of the 12-byte total number of LBAs written to the device |
| 244 | Total LBAs Read Expanded | The upper 5 bytes of the 12-byte total number of LBAs read from the device |
| 249 | NAND_Writes_1GiB | Total NAND Writes. Raw value reports the number of writes to NAND in 1 GB increments |
| 250 | Read Error Retry Rate | Count of errors appearance while reading data from a disk |